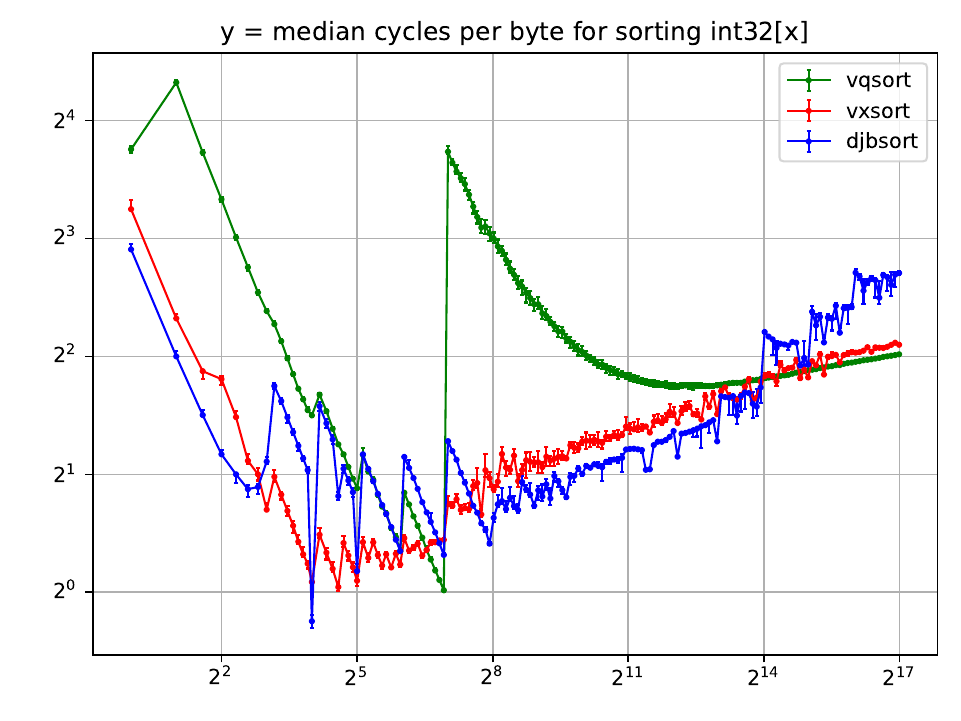
2022.06.08 01:05:01 (1534310488732930048) from Daniel J. Bernstein:
Posted an AVX2-vectorized-sorting benchmarking script https://cr.yp.to/software/sortbench-20220607.tar.gz covering djbsort, vxsort, vqsort. (vxsort and vqsort also support AVX-512.) The middle part of this Skylake graph is the part that matters for crypto, and also the base case for larger quicksort etc.
2022.06.08 01:20:21 (1534314348830773248) from Daniel J. Bernstein:
The graph says a lot about performance. For example, the blue increases on the right are from many L1 cache misses. Maybe there has to be a tradeoff between constant-time and fast; but should try optimizing the sorting-network array-access pattern, as noted in the documentation.
2022.06.08 01:25:11 (1534315566525194240) from Daniel J. Bernstein:
Assuming I haven't misunderstood how to use vqsort: The graph shows vqsort often losing badly to vxsort-cpp, and never beating it by much. The green mountain in the middle of the graph is a striking performance regression. Fixing it would also improve vqsort for larger sizes.
2022.06.08 01:54:22 (1534322910990508032) from Daniel J. Bernstein:
In current vqsort, the base case is (for AVX2) a size-128 sorting network, where vqsort looks slightly better than previous work... because it fully unrolls the code for that size. Can't fit many such sizes in insn caches. djbsort and vxsort put more effort into code compression.
2022.06.08 02:05:05 (1534325605570957313) from Daniel J. Bernstein:
Since vqsort manages to catch up to vxsort for large sizes despite being worse in the base case, the vqsort splits must be faster than the vxsort splits, so vxsort could gain speed by adopting those. For djbsort, this is ruled out by the requirement of being constant-time.
2022.06.08 02:32:08 (1534332411185537024) from Daniel J. Bernstein:
Regarding benchmarks, it's important to realize that measuring only size 128 misses opportunities to speed up other quicksort base-case sizes, and measuring only size 1M adds unnecessary fog by adding many levels of splits to the base cases. Many sizes appear; measure them all!